Anki to popularny, darmowy program do nauki języków obcych metodą spaced repetition, czyli „fiszek”. W dużym skrócie, to takie „karty” do nauki, po jednej stronie mamy słowo po polsku, po drugiej po angielsku. Oglądamy jedną stronę, szukamy w głowie odpowiedzi, potem patrzymy na drugą stronę i sprawdzamy, czy odpowiedzieliśmy dobrze.
Czy taka metoda nauki dobrze sprawdzi się do nauki programowania?
Używam Anki od 15 lat i uważam, że bardzo pomaga w językach obcych, ale do niedawna byłem sceptyczny co do zastosowania na innych polach. Mimo że czytałem o ludziach używających programu do nauki matematyki (stąd wbudowana obsługa równań w TeXu) lub przygotowania do egzaminów na studiach medycznych.
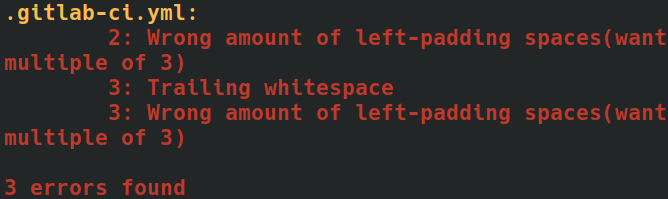
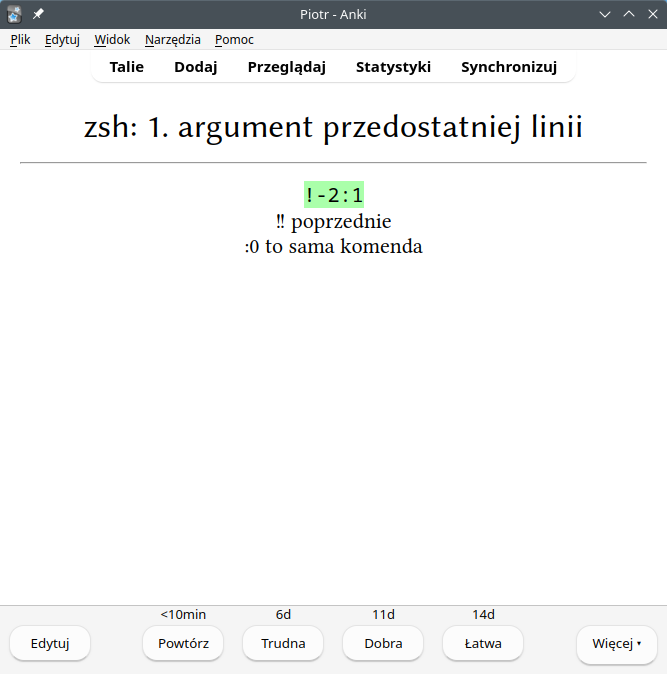
Wydawało mi się, że pamięciowe wkuwanie nie ma nic wspólnego z zawodowym programowaniem (szkoda, że przeciwne podejście wciąż zdarza się w kuriozalnych procesach rekrutacji, ale to osobny temat). Tak było do czasu, aż złapałem się, że szukam na własnym blogu, jak wkleić parametr w Zsh, albo zaglądam do notatek, żeby sprawdzić, jak sprawnie przesuwać kursor w vimie. Co mi ze skrótu, jeśli muszę czytać objaśnienia, zanim go użyję? Tak nie może być. Postanowiłem użyć Anki do nauki poleceń, których nie mogę zapamiętać.
Okazało się, że narzędzie sprawdza się dobrze również w nauce ezoterycznych kombinacji klawiszy. Postęp był widoczny szybko: po kilku dniach zacząłem w prawdziwej pracy używać skrótów, które wcześniej omijałem, bo nie mogłem sobie ich przypomnieć. Zapamiętałem też tą metodą zupełnie inne rzeczy.
W dalszej części opowiem krótko, jak skonfigurowałem Anki, oraz trochę więcej o tym, czemu uważam, że to dobre narzędzie do nauki takich skrótów.
Czytaj dalej „Anki w nauce terminala, edytorów i programowania”