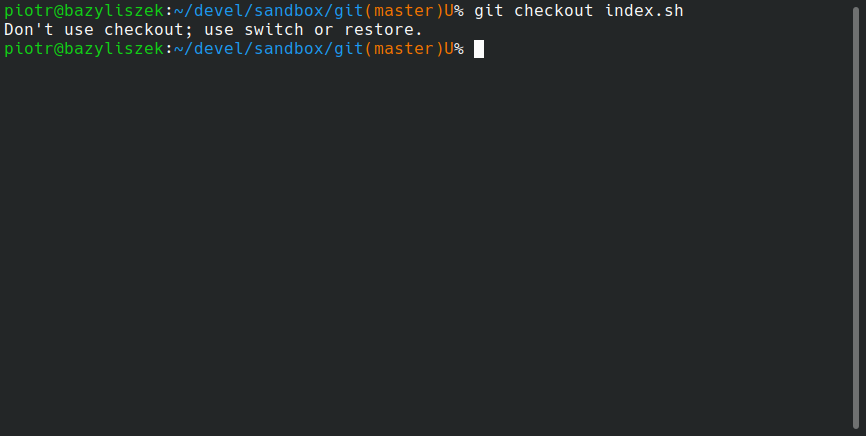
Git to obecnie w zasadzie synonim systemu kontroli wersji – mało kto dzieli się otwartym kodem w inny sposób, ale też przy pracy nad zamkniętym komercyjnym kodem coraz rzadziej widzi się inne rozwiązania. Ważąc wszystkie za i przeciw, jest to prawdopodobnie bardzo pozytywna zmiana, jeśli przypomnieć sobie z jakimi potworkami zmuszeni byli nie tak dawno temu pracować programiści. Tyle że biorąc Gita za coś oczywistego możemy zacząć zapominać o jego wadach – a nie jest to idealny system kontroli wersji. Narzędzie stworzone przez Linusa Torvaldsa było chyba od początku mocno krytykowane za user experience: że ma dziwną logikę, podporządkowaną bardziej sposobowi działania samego oprogramowania, a nie temu, jak pracę z wersjami widzi człowiek. Najmocniej przejawia się to w komendach, które robią kilka bardzo odległych koncepcyjnie rzeczy w zależności od podanych argumentów. Na przykład checkout: czasem odrzuca niezacommitowane zmiany w plikach, a czasem zmienia gałęzie.
Znalazłem ostatnio instrukcje, jak pozbyć się git checkout, korzystając z nowych poleceń switch i restore. W dalszej części opowiem, czemu warto tak zrobić i jak wygląda praca na nowy sposób.
Czytaj dalej „Koniec z git-checkout”