
Jest to raczej rzadka sytuacja, ale może zdarzyć się, że potrzebujecie do Javy przekazać system property, w którym jest spacja. Niestety, może być z tym kłopot. Czasem na drodze stoją Dockery, zmienne środowiskowe i shellowe skrypty uruchamiające. Na wypadek tak niekorzystnych warunków zaprezentuję opcję @, która pozwala uciec od shellowych zawiłości i wczytać opcje Javy z pliku.
Tag: linia komend
Anki w nauce terminala, edytorów i programowania
Anki to popularny, darmowy program do nauki języków obcych metodą spaced repetition, czyli „fiszek”. W dużym skrócie, to takie „karty” do nauki, po jednej stronie mamy słowo po polsku, po drugiej po angielsku. Oglądamy jedną stronę, szukamy w głowie odpowiedzi, potem patrzymy na drugą stronę i sprawdzamy, czy odpowiedzieliśmy dobrze.
Czy taka metoda nauki dobrze sprawdzi się do nauki programowania?
Używam Anki od 15 lat i uważam, że bardzo pomaga w językach obcych, ale do niedawna byłem sceptyczny co do zastosowania na innych polach. Mimo że czytałem o ludziach używających programu do nauki matematyki (stąd wbudowana obsługa równań w TeXu) lub przygotowania do egzaminów na studiach medycznych.
Wydawało mi się, że pamięciowe wkuwanie nie ma nic wspólnego z zawodowym programowaniem (szkoda, że przeciwne podejście wciąż zdarza się w kuriozalnych procesach rekrutacji, ale to osobny temat). Tak było do czasu, aż złapałem się, że szukam na własnym blogu, jak wkleić parametr w Zsh, albo zaglądam do notatek, żeby sprawdzić, jak sprawnie przesuwać kursor w vimie. Co mi ze skrótu, jeśli muszę czytać objaśnienia, zanim go użyję? Tak nie może być. Postanowiłem użyć Anki do nauki poleceń, których nie mogę zapamiętać.
Okazało się, że narzędzie sprawdza się dobrze również w nauce ezoterycznych kombinacji klawiszy. Postęp był widoczny szybko: po kilku dniach zacząłem w prawdziwej pracy używać skrótów, które wcześniej omijałem, bo nie mogłem sobie ich przypomnieć. Zapamiętałem też tą metodą zupełnie inne rzeczy.
W dalszej części opowiem krótko, jak skonfigurowałem Anki, oraz trochę więcej o tym, czemu uważam, że to dobre narzędzie do nauki takich skrótów.
Czytaj dalej „Anki w nauce terminala, edytorów i programowania”Plik .env do tajnych kluczy w IntelliJ i konsoli
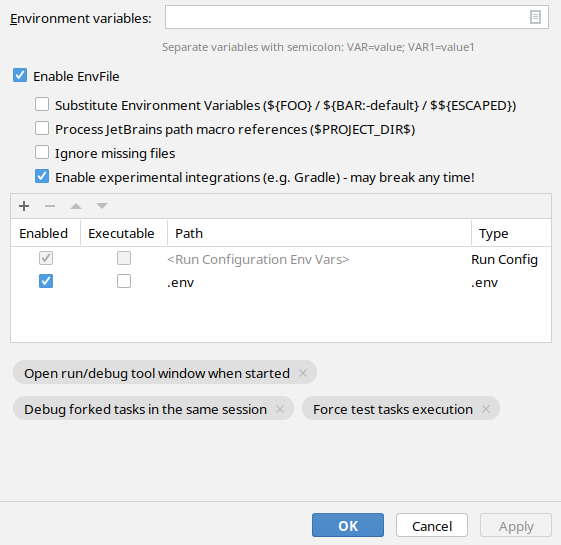
Czasem zachodzi potrzeba pracy przez krótki czas z zasobami, do których nie mamy na co dzień dostępu. Coś zachowuje się dziwnie, dostajemy tymczasowy dostęp do jakiegoś API, żeby móc wysyłać zapytania z naszego laptopa i szybciej dojść, co poprawić. Mamy jedno tajne hasło, albo coś bardziej rozbudowanego, na przykład zestaw 7 różnych parametrów: client ID, client secret, jakiś token, jakiś specjalny URL i inne cuda niewidy.
Jak wygodnie pracować w takich warunkach?
W artykule krótko opowiem o jednym z rozwiązań: plikach .env . Jaki mają format, jak z nich korzystać (w terminalu i IDE, na przykład odpalając testy albo inne taski z wykorzystaniem Gradle’a), czemu są wygodne.
Wyciąganie danych z HTML-a za pomocą htmlq
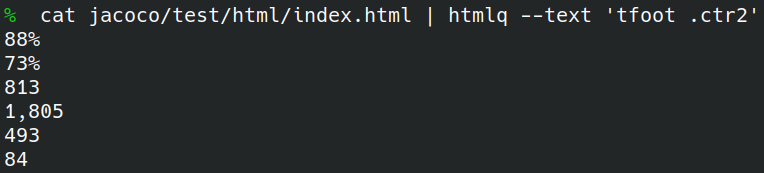
Pisałem wcześniej o yq, czyli programie w stylu awka/seda do wyciągania danych z YAML-a. Do JSON-a jest znany szerzej jq. Przydają się do drobnych automatyzacji na własny użytek, ale też do skryptów uruchamianych na CI. Szukałem ostatnio czegoś takiego do HTML-a i zdziwiłem się, bo większość odpowiedzi sugerowała odpalanie jakichś długaśnych one-linerów ręcznie kasujących tagi HTML. Nie, dziękuję! Na szczęście, 2 lata temu (dopiero??) pojawił się projekt htmlq, reklamujący się bardzo trafnym sloganem:
Like jq, but for HTML. Uses CSS selectors to extract bits of content from HTML files.
Brzmi nieźle, prawda?
W dalszej części pokażę krótko, na ile wygodne jest użycie, co robi się łatwo, a co nie.
Działamy w terminalu, więc pojawią się też inne narzędzia, jak awk, którym usuniemy puste linie psujące czytelność (nieoczywista sztuczka, którą moim zdaniem warto znać). Nasz „query language” to CSS, co z jednej strony ma zalety (każdy używał kiedyś CSS-a), ale też wyjdą pewne problemy (bo to CSS).
Czytaj dalej „Wyciąganie danych z HTML-a za pomocą htmlq”Wgląd w konsolowy pipe
Kontynuując temat sprawnego używania terminala. Czasem przy pisaniu pipe’a brakuje podglądu tego, co dzieje się między krokami:
curl http://localhost:8080/admins | awk get-username.awk | ./delete.sh
Łatwym sposobem wydrukowania danych na danym etapie jest użycie tee podłączonego do stderr:
curl http://localhost:8080/admins | awk get-username.awk | tee /dev/stderr | ./delete.sh
Bonusowy content: linki do materiałów do uczenia się obsługi shella.
Czytaj dalej „Wgląd w konsolowy pipe”Konsola: sprytne przeklejanie argumentów

Wpisujesz komendę w konsoli, uruchamiasz… i coś jest nie tak. Trzeba poprzednie polecenie zmodyfikować i odpalić ponownie. Co teraz? Wpisywanie wszystkiego od zera nie wchodzi w grę. Można pomóc sobie myszą, zaznaczać, kopiować, wklejać, dusić backspace – są jednak szybsze opcje, niewymagające odrywania rąk od klawiatury. Opowiem o nich, zaczynając od tych wspominanych w większości poradników (jak !! i !$), kończąc na rzeczach mniej znanych: odwoływaniu się do argumentów po indeksie i usuwaniu z nich rozszerzeń i fragmentów ścieżki. Opisywane mechanizmy działają w Zsh i Bashu. Część może uprościć pisanie skryptów.
Wyciąganie danych z YAML-a za pomocą yq

yq to konsolowe narzędzie do manipulacji YAML-em. Czemu warto je znać?
YAML jest teraz wszędzie – konfiguruje się nim pipeline’y CI, sposób deploymentu, pojedyncze aplikacje. Przewagą tego języka nad na przykład JSON-em jest możliwość unikania duplikacji przez zdefiniowanie powtarzającego się kodu w jednym miejscu i „dołączanie” go wielokrotnie. Mając konfigurację CI GitLaba:
.jvm_job: &jvm_job
image: openjdk:11-jdk-slim
.gradle_job: &gradle_job
<<: *jvm_job
tags:
- medium
check:
stage: test
image: openjdk:11-jdk
script:
- ./gradlew check
<<: *gradle_job
deploy_cit:
<<: *cit_variables
<<: *deploy_job
# a dookoła jeszcze tak z 50 różnego rodzaju jobów
możliwości YAML-a umożliwiają nam dzielenie konfiguracji joba na reużywalne kawałki i komponowanie z nich ostatecznych jobów. Z drugiej strony dużo trudniejsze staje się dla czytającego odpowiedzenie na pytanie, co tak właściwie robi dany job: we fragmencie wyżej mamy zarówno coś w rodzaju dłuższej hierarchii dziedziczenia (check) jak i coś w rodzaju wielokrotnego dziedziczenia (deploy_cit). Konfiguracja GitLaba definiuje prawie 30 parametrów konfiguracyjnych jobów, więc rzeczywiste pliki są zazwyczaj dużo bardziej skomplikowane niż przykład wyżej. Nagle od tego, czy umiem w głowie merge’ować spore struktury danych zależy to, czy wprowadzę błąd w konfiguracji, czy nie.
Idealnie byłoby, gdyby jakieś narzędzie wypluwało mi ostateczną postać pliku konfigurowaniu, po wstawieniu wszystkiego na miejsce i zmerge’owaniu. Tyle, że jest z tym bieda: taki GitLab na przykład chwali się w tym miesiącu wizualizacją pipeline’u generowaną z edytowanej konfiguracji, ale konkretnych parametrów tam nie ma. Jeśli ciekawi mnie, jaki image będzie użyty w jobie check, wizualizacja GitLaba nie przybliży mnie ani o krok do odpowiedzi. Tak w ogóle to odpowiedź brzmi: nie ten image, jaki zamierzył sobie autor kodu, więc pewnie wszystko nie działa.
Ogólnie: systemy przyjmujące YAML-ową konfigurację często nie oferują dobrej możliwości zrozumienia skutków zaaplikowania tej konfiguracji. Dobrze jest znać więc coś niskopoziomowego, nieprzywiązanego do tej czy tamtej aplikacji, coś, co potrafi operować na dowolnym YAML-u, niezależnie od jego przeznaczenia.
Czytaj dalej „Wyciąganie danych z YAML-a za pomocą yq”Vim jako edytor Gita
Najczęściej w pracy do tworzenia commitów używam IDE IntelliJ. Jest to naprawdę świetne narzędzie: pozwala w jednym oknie dialogowym przejrzeć jeszcze raz diff zmian, pominąć niektóre pliki albo nawet części plików, sprawdza pisownię, podpowiada poprzednie opisy zmian. Czasem jednak zdarza mi się tworzyć commity bezpośrednio z linii komend — zwłaszcza gdy projekt nie jest pisany w Javie/Kotlinie, nie chce mi się czekać na kobyłę, jaką jest IntelliJ — zmieniam coś prostym edytorem tekstowym lub graficznym i odpalam wprost git commit. Domyślnie w Ubuntu przy tworzeniu commitu otwiera się bardzo prosty edytor nano. Ja sam używałem nano z Gitem od wielu lat, od pół roku jednak opisy zmian i podobne teksty zmieniam w Vimie. Napiszę teraz krótko, czemu moim zdaniem to świetny wybór i co ustawić, żeby dać szansę takiej kombinacji.
Praca ze schowkiem z linii komend

Efektywna praca ze schowkiem systemowym to nie tylko umiejętność szybkiego wciskania Ctrl+C i Ctrl+V — przydatna jest też na przykład wiedza, jak korzystać ze schowka w terminalu.
Warto oglądać dobrych programistów przy pracy, pozwala to nauczyć się rzeczy, o których istnieniu po prostu nie wiemy. Ostatnio uderzyło mnie to przy słuchaniu prezentacji twórców Springa — w pewnym momencie Rob Winch potrzebuje zakodować hasło, a potem wkleić je w jedno pole w IDE (patrz 30-sekundowy fragment nagrania). Do tej pory gdy miałem zrobić coś podobnego, uruchamiałem komendę wypisującą coś w terminalu, zaznaczałem tekst myszą i kopiowałem. Upierdliwa rzecz, trzeba oderwać ręce od klawiatury, można kliknąć w złym miejscu, a z dala od biurka, na przykład na chodzącym jak spróchniała deska touchpadzie Lenovo, taka prosta czynność staje się utrapieniem. Natomiast Rob wykonał po prostu w terminalu:
spring encodepassword password | copy
Jak możemy uzyskać coś takiego na naszej maszynie? Sprawa jest nieco skomplikowana, bo nie ma jednej metody dla wszystkich systemów.
Czytaj dalej „Praca ze schowkiem z linii komend”